Improving Website reliability with Nginx timeout configuration
Last year I gave a presentation for the London User Group about zero-downtime deployment configurations that could be implemented with Ngnix, HAproxy and Unicorn. The video of the talk can be found at the Skillsmatter website here.
Continuing on this topic, we recently had an issue with one of our back-end servers, in which it would stick and take longer than 60 seconds to respond to each request from the front-end server. When this happened, the front-end server would service the maximum number of concurrent connections and then refuse new connections as all of the resources were held by the back-end server. The configuration of the system is shown below:
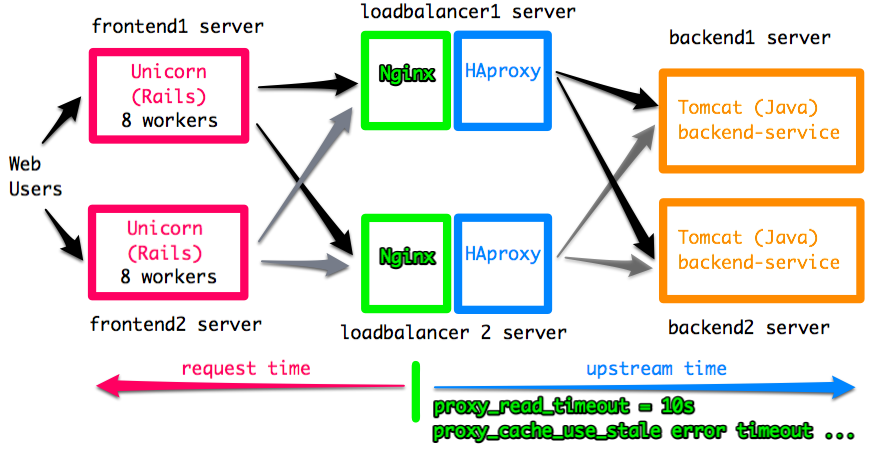
The front-end server uses Unicorn and has a number of process workers (16 in our case) to handle client requests. Each worker can only serve one client request at a time; and a worker is not available for additional work whilst the back-end server is processing the worker's request. The problem occurred when the back-end took an unusually long time to respond; whilst the Unicorn worker is waiting for a response from the back-end server, the website clients experience down-time. This meant that when the back-end server malfunctioned, each request would take a long time, causing all of the Unicorn workers to become busy and the website to return the error code, '503, Service Unavailable,' to the browser.
Fortunately, Nginx can handle this situation by timing out upstream requests that take more than a predefined threshold and by serving stale cache data instead of returning an error code. In our case, most of the back-end calls would take less than 1 second, so it was safe to set the timeout to 10 seconds. This configuration is added to the Nginx configuration file as follows:
location ~ ^/_backend-service_/ {
proxy_pass "_http://backendserver.ourdomain_";
proxy cache _cache_zone_name_;
proxy_cache_key $uri$is_args$args;
proxy_cache_valid 200 302 10m;
proxy_read_timeout 10s;
proxy_cache_use_stale error timeout http_500 http_503;
}
In our current setup we execute a special request to update our system every evening, and this call takes 20 seconds to execute. For this particular call, we need to create an exception location with the default value of proxy_read_timeout set to 60s. We do this in the Nginx configuration file below. It is important to note that the proxy_pass statement has to be included within the new location because this type of statement is not inherited from the parent location.
location ~ ^/_backend-service_/ {
location ~ exception-url$ {
proxy_pass "http://backendserver.ourdomain";
proxy_read_timeout 60s;
}
proxy_pass "_http://backendserver.ourdomain_";
proxy cache _cache_zone_name_;
# ...
proxy_cache_use_stale error timeout http_500 http_503;
}
By implementing this timeout configuration, we successfully mitigate the problem of the back-end service taking down the front-end under unforeseen error conditions.
Jairo Diaz
 Jairo is the founder and managing director of CodeScrum Ltd - a company dedicated to creating user centric digital services and products. Our clients include government agencies, newspapers, universities, retail businesses, charities and leading startups.
Jairo is the founder and managing director of CodeScrum Ltd - a company dedicated to creating user centric digital services and products. Our clients include government agencies, newspapers, universities, retail businesses, charities and leading startups.